 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIVESPATIAL: A Benchmark for Spatiotemporal Intelligence in VLMs for Autonomous Driving
May 22, 2026Spatiotemporal intelligence in autonomous driving (AD) requires an agent to integrate multi-view observations into a coherent scene representation, maintain object continuity across viewpoints and time, and reason about spatial relations, interactions, and future dynamics. However, existing AD vision-language benchmarks largely focus on single-view, static, ego-centric, or single-source question answering, leaving it unclear whether current Vision-Language Models (VLMs) can truly construct and reason over dynamic driving scenes. We introduce DriveSpatial, a benchmark of 15.6K human-verified QA pairs across 20 tasks from five large-scale AD datasets. DriveSpatial evaluates four abilities: Cognitive Scene Construction, Multi-view Relational Understanding, Temporal Reasoning, and Generalization. Unlike prior benchmarks, DriveSpatial is generated from a dynamic multi-relational scene graph that encodes object states, spatial relations, interactions, camera visibility, and temporal correspondences, enabling QA pairs that enforce genuine cross-view and spatiotemporal reasoning. Evaluating 15 representative VLMs reveals a substantial human-model gap: the strongest model trails humans by 28.4 points, with Cognitive Scene Construction emerging as the key bottleneck. Further diagnostics show that language-only prompting is insufficient, while explicit BEV grounding consistently improves performance. These results suggest that current VLMs lack the scene-construction ability needed for reliable spatiotemporal driving intelligence. DriveSpatial and its construction pipeline will be released to support future research.
CodeGraphVLP: Code-as-Planner Meets Semantic-Graph State for Non-Markovian Vision-Language-Action Models
Apr 24, 2026Vision-Language-Action (VLA) models promise generalist robot manipulation, but are typically trained and deployed as short-horizon policies that assume the latest observation is sufficient for action reasoning. This assumption breaks in non-Markovian long-horizon tasks, where task-relevant evidence can be occluded or appear only earlier in the trajectory, and where clutter and distractors make fine-grained visual grounding brittle. We present CodeGraphVLP, a hierarchical framework that enables reliable long-horizon manipulation by combining a persistent semantic-graph state with an executable code-based planner and progress-guided visual-language prompting. The semantic-graph maintains task-relevant entities and relations under partial observability. The synthesized planner executes over this semantic-graph to perform efficient progress checks and outputs a subtask instruction together with subtask-relevant objects. We use these outputs to construct clutter-suppressed observations that focus the VLA executor on critical evidence. On real-world non-Markovian tasks, CodeGraphVLP improves task completion over strong VLA baselines and history-enabled variants while substantially lowering planning latency compared to VLM-in-the-loop planning. We also conduct extensive ablation studies to confirm the contributions of each component.
Accenture at CheckThat! 2021: Interesting claim identification and ranking with contextually sensitive lexical training data augmentation
Jul 12, 2021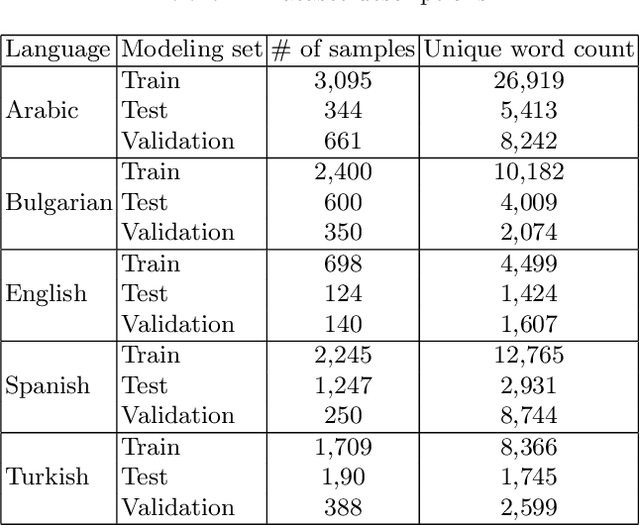
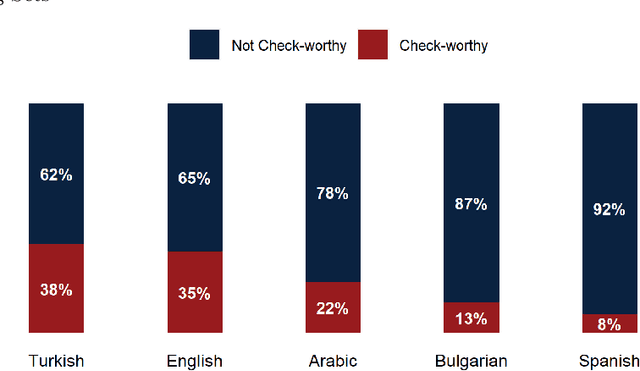
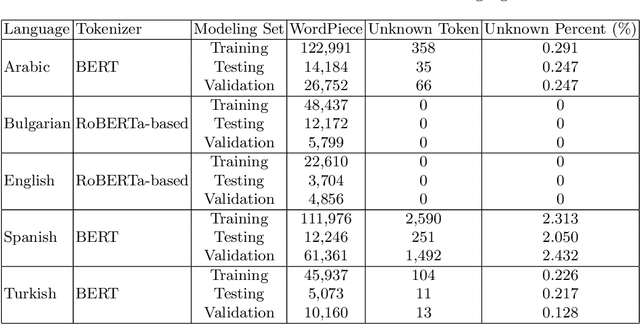
This paper discusses the approach used by the Accenture Team for CLEF2021 CheckThat! Lab, Task 1, to identify whether a claim made in social media would be interesting to a wide audience and should be fact-checked. Twitter training and test data were provided in English, Arabic, Spanish, Turkish, and Bulgarian. Claims were to be classified (check-worthy/not check-worthy) and ranked in priority order for the fact-checker. Our method used deep neural network transformer models with contextually sensitive lexical augmentation applied on the supplied training datasets to create additional training samples. This augmentation approach improved the performance for all languages. Overall, our architecture and data augmentation pipeline produced the best submitted system for Arabic, and performance scales according to the quantity of provided training data for English, Spanish, Turkish, and Bulgarian. This paper investigates the deep neural network architectures for each language as well as the provided data to examine why the approach worked so effectively for Arabic, and discusses additional data augmentation measures that should could be useful to this problem.